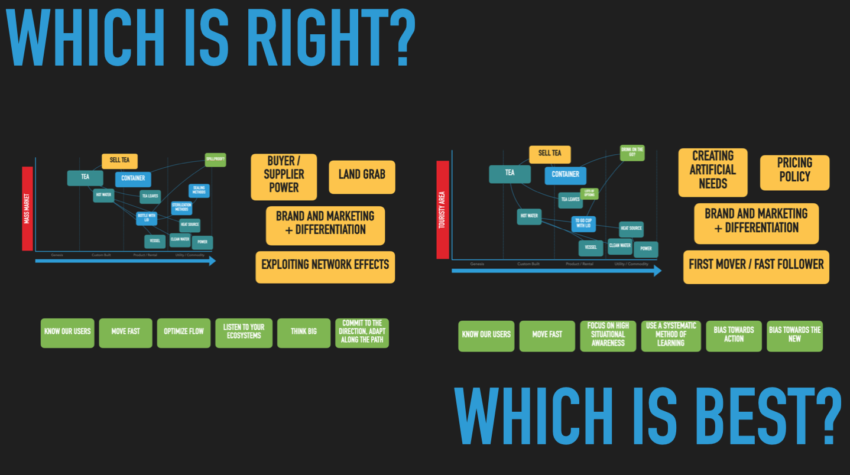
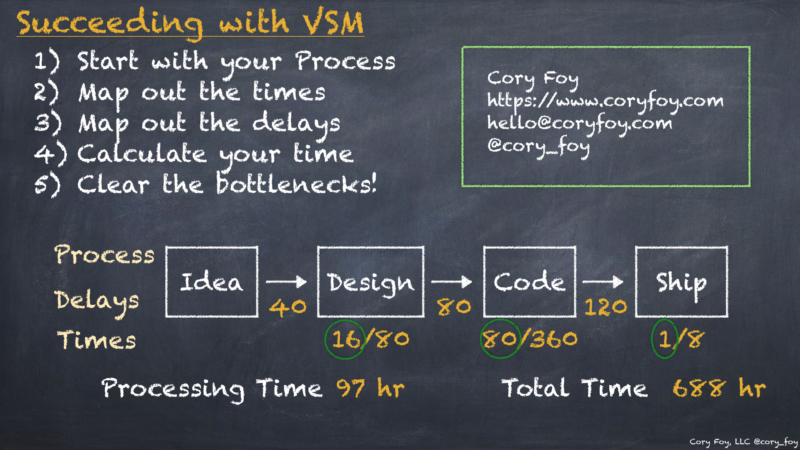
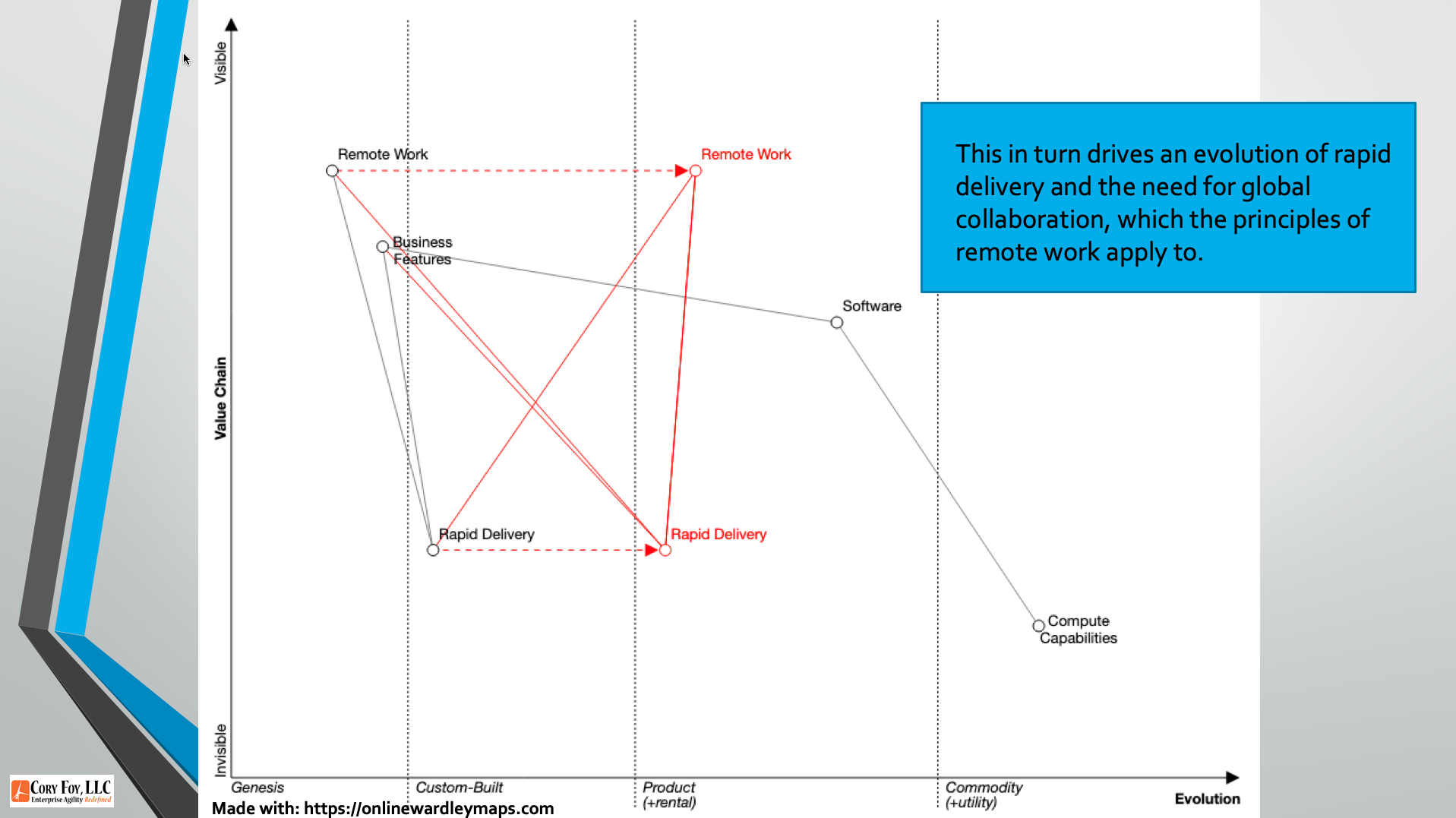
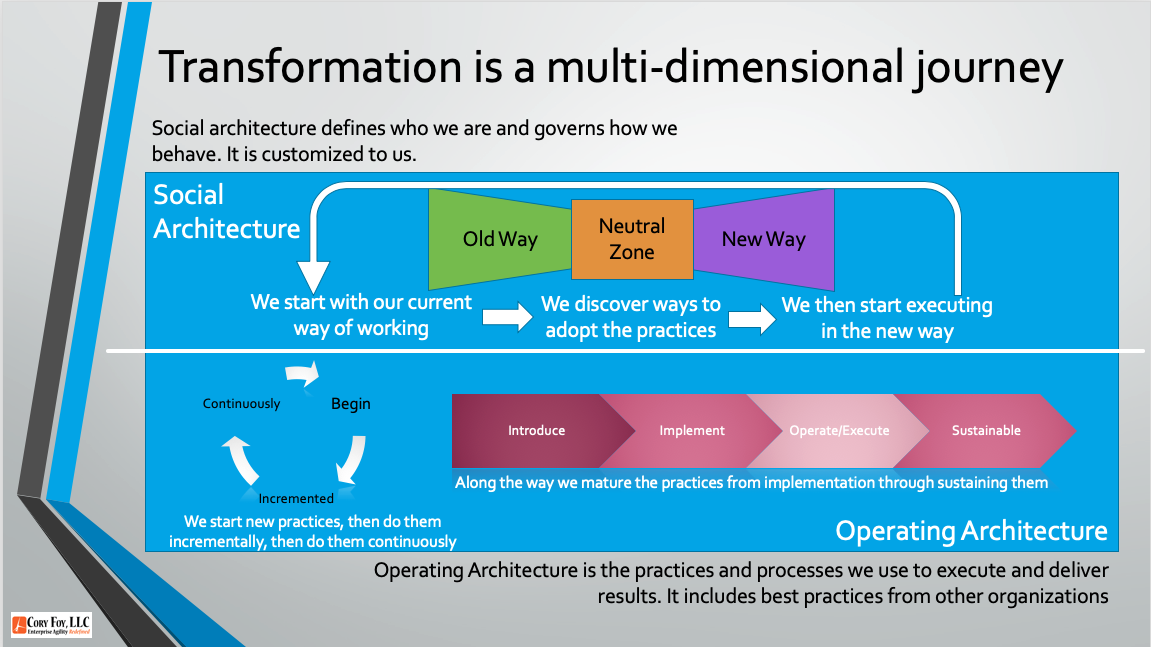
A talk from the November 2022 AgileRTP meetup covering product development with Wardley Mapping. Your browser does not support the video tag. And if you’d prefer, you can download a PDF of the slides. Key links from the video: My free Wardley Map videos and resources Simon’s Book The Wardley Map wiki The Wardley Map…